
Evaluating the Factual Consistency of Abstractive Text Summarization (요약 모델의 사실 관계 일관성 평가)
- 논문 제목 : Evaluating the Factual Consistency of Abstractive Text Summarization, Kryściński et al. (2020)
- 구현 코드
1. Introduction
현재 요약 분야에서 제기되는 문제점들은 다음과 같다.
- 사실 관계 일관성 등 중요한 정보를 무시하는 불충분한 평가 지표
- 노이즈가 많아서 태스크에 집중하지 못하도록 하는 데이터셋
- 특정 도메인에 치우친 데이터로 인한 훈련 편향
논문은 이 중에서 원본 문서와 생성된 요약 사이의 사실 관계 일관성에 대해 다루고 있다. 최근 연구에 따르면 추상 요약 모델이 생성한 요약문의 약 30% 가 사실 관계에서 일치하지 않았으며, 이로 인해 요약 모델의 실제 활용에 큰 제약으로 나타나고 있다.
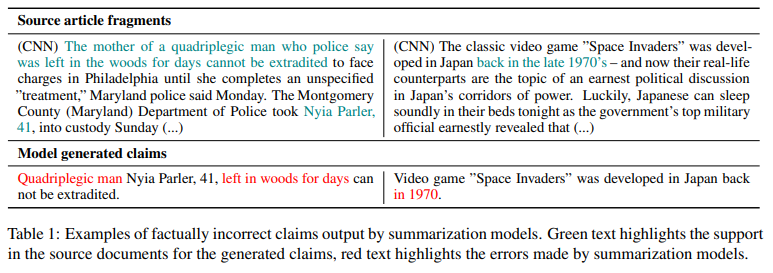
저자진은 BERT를 기반으로 사실 관계 일관성을 판단하는 weakly-supervised 모델을 제안한다. 훈련 데이터는 원본 문서에 규칙 기반 변환을 여러번 적용하여 생성하였다.
2. Related Work
-
Goodrich et al. (2019) : 사실 관계 정확도를 원본 문서와 요약문에서 추출한 사실들 사이의 precision으로 정의함. 긍정적인 결과를 얻었으나, 부정문이나 유의어 등의 관계를 파악하지 못하는 단점이 있다.
-
Falke et al. (2019) : 요약문 생성에 beam search를 사용하여 여러 후보군을 생성한 뒤 요약문별 정확도 점수를 산출하여 가장 높은 후보를 반환한다.
-
Cao et al. (2018) : 듀얼 인코더를 사용, 각각 본문과 포함된 사실들을 인코딩한다. 생성 과정에서 디코더는 인코딩된 본문과 사실들 모두에 attend하여 사실들을 담아낼 수 있도록 강제한다.
3. Methods
SOTA급 요약 모델들에서 발생하는 사실 관계 불일치 오류들을 분석하며 알게된 것들은 다음과 같다.
- 사실 관계 일치도를 체크하기 위해 요약문을 원본 문서의 각 문장들과 비교하는 것은 불충분한데, 이는 한 문장만 봤을 때는 의미가 모호할 수 있기 때문이다.
- 요약 모델에서 발생하는 오류는 주로 고유명사나 숫자, 대명사 등을 잘못 사용하는 것이다. 반면 부정이나 일반 상식 오류는 잘 발생하지 않는다.
이들을 고려하여 저자는 ‘문서-문장’ 단위의 사실 관계 확인 방식을 사용하고자 한다.
3.1 Training Data
현재 사실 관계 일관성을 위해 공개된 데이터가 없으며, 이를 인력을 동원하여 생성하는 건 너무 비용이 많이 들기에 저자들은 다른 방법을 사용한다.
- 먼저 요약 모델의 성능을 평가하기 위한 도메인에서 원본 문서들을 구축한다.
- 하나의 문장을 샘플링한 후, 다양한 텍스트 변환에 통과시켜 ‘긍정’ 혹은 ‘부정’로 분류되는 새로운 문장을 생성한다.
이 과정에서 사용한 텍스트 변환들은 크게 의미 불변 변환들(\(\mathcal{T}^+\))과 의미 변환 변환(\(\mathcal{T}^-\))으로 나뉘며, 이를 사용해서 CORRECT와 INCORRECT 라벨이 붙은 새로운 문장들을 만들어 낸다.

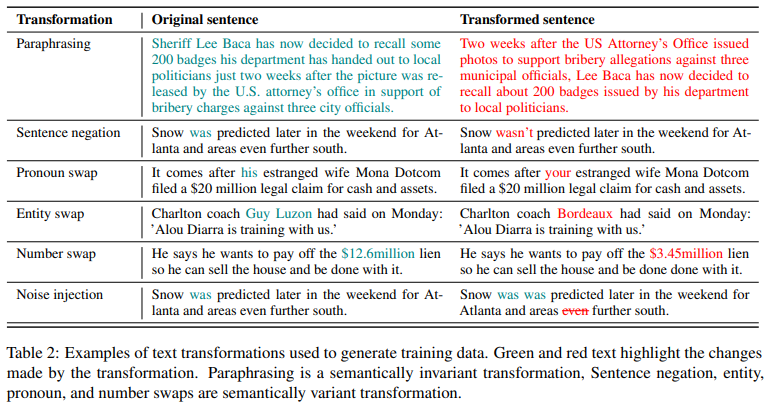
이때 사용한 변환들은 다음과 같다.
Paraphrasing (의미 불변)
NMT를 사용한 back translation을 이용, 영어 -> 다른 언어 -> 영어의 번역 과정을 통해 주어진 문장을 변환한다. 이 논문에서는 구글 번역 API를 사용하였다.
# translate to intermediate language and back
claim_trans = self.translator.translate(claim.text, target_language=dst_lang, format_="text")
claim_btrans = self.translator.translate(claim_trans["translatedText"], target_language=self.src_lang, format_="text")
Entity and Number swapping (의미 변환)
SpaCy의 NER tagger를 이용하여 주어진 문장과 원본 문서의 모든 엔티티를 추출 후 이들을 이름 관련 엔티티와 숫자 관련, 그리고 날짜 관련 엔티티로 분류한다. 주어진 문장에서 엔티티를 하나 선택한 후, 이와 같은 분류에 속한 문서의 엔티티로 대체한다.
text_ents = [ent for ent in text.ents if ent.label_ in self.categories]
claim_ents = [ent for ent in claim.ents if ent.label_ in self.categories]
# choose entity to replace and find possible replacement in source
replaced_ent = random.choice(claim_ents)
candidate_ents = [ent for ent in text_ents if ent.text != replaced_ent.text and ent.text not in replaced_ent.text and replaced_ent.text not in ent.text]
swapped_ent = random.choice(candidate_ents)
Pronoun swapping (의미 변환)
잘못된 대명사 사용을 찾아내기 위해서 문장에 등장하는 대명사를 사전에 정의한 클래스 내의 다른 대명사로 변환한다.
self.class2pronoun_map = {
"SUBJECT": ["you", "he", "she", "we", "they"],
"OBJECT": ["me", "you", "him", "her", "us", "them"],
"POSSESSIVE": ["my", "your", "his", "her", "its", "out", "your", "their"],
"REFLEXIVE": ["myself", "yourself", "himself", "itself", "outselves", "yourselves", "themselves"]
}
claim_pronouns = [token for token in claim if token.text.lower() in self.pronouns]
# find pronoun replacement
chosen_token = random.choice(claim_pronouns)
chosen_class = self.pronoun2class_map[chosen_token.text.lower()]
candidate_tokens = [token for token in self.class2pronoun_map[chosen_class] if token != chosen_token.text.lower()]
# swap pronoun and update indices
swapped_token = random.choice(candidate_tokens)
Sentence negation (의미 변환)
부정 문장에 대해 학습하기 위해 부정 변환을 사용한다. 먼저 문장에서 조동사를 찾고, 그 중 하나를 반대 형으로 변환한다(긍정은 부정으로, 부정은 긍정으로).
self.__negatable_tokens = ("are", "is", "was", "were", "have", "has", "had",
"do", "does", "did", "can", "ca", "could", "may",
"might", "must", "shall", "should", "will", "would")
candidate_tokens = [token for token in claim if token.text in self.__negatable_tokens]
# choose random token to negate
negated_token = random.choice(candidate_tokens)
negated_ix = negated_token.i
# check whether token is negative
is_negative = False
if claim[negated_ix + 1].text in ["not", "n't"]:
is_negative = True
# negate token
claim_tokens = [token.text_with_ws for token in claim]
if is_negative:
# delete next token (might be "not", "n't")
claim_tokens.pop(negated_ix + 1)
else:
if claim[negated_ix].text.lower() in ["am", "may", "might", "must", "shall", "will"]:
negation = "not "
else:
negation = random.choice(["not ", "n't "])
# insert negation after the candidate token
claim_tokens.insert(negated_ix + 1, negation)
Noise injection (공통)
신경망을 통해 생성된 요약문들은 여러가지 형태의 노이즈를 포함하고 있다. 사실 관계 파악 모델이 이런 오류에 강건해지도록 훈련 데이터에 의도적으로 노이즈를 더해주는데, 이는 각 토큰을 복제하거나 아니면 삭제하는 방식으로 구현한다.
위 변환들의 구체적인 예시는 다음과 같다.
3.2 Development and test data
훈련 데이터와는 다르게 평가 및 테스트 데이터셋은 직접 구축하였다. 먼저 SOTA 요약 모델을 이용하여 요약문을 생성한 뒤, (문서, 요약문) 쌍을 직접 저자들이 검증하여 라벨을 붙였다. 이렇게 구축된 데이터셋은 평가셋 931개, 테스트셋 503개이다.
크라우드 소싱 등으로 더 많은 데이터를 구축하려고 하였으나, 결과물의 질이 너무 낮아서 사용하지 않기로 하였다.
3.3 Models
이 논문에서는 uncased BERT base 모델에 (문서, 요약문)을 입력으로 넣고 [CLS] 토큰 임베딩을 MLP에 통과시켜 CONSISTENT/INCONSISTENT 분류를 수행한다. 이 모델을 FactCC라고 하고, 여기에 추가로 실수가 발생할 수 있는 span을 판단하는 모델을 FactCCX라고 부른다.
class BertPointer(BertPreTrainedModel):
def __init__(self, config):
super(BertPointer, self).__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config)
# classifiers
self.label_classifier = nn.Linear(config.hidden_size, self.config.num_labels)
def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None,
position_ids=None, head_mask=None,
ext_mask=None, ext_start_labels=None, ext_end_labels=None,
aug_mask=None, aug_start_labels=None, aug_end_labels=None,
loss_lambda=1.0):
# run through bert
bert_outputs = self.bert(input_ids, position_ids=position_ids, token_type_ids=token_type_ids,
attention_mask=attention_mask, head_mask=head_mask)
# label classifier
pooled_output = bert_outputs[1]
pooled_output = self.dropout(pooled_output)
label_logits = self.label_classifier(pooled_output)
4 Experiments
4.1 Experimental Setup
훈련 데이터는 3.1 에서 설명한 방법론을 CNN/DM 데이터셋에 적용하여 얻는다.총 1,003,355개의 훈련 데이터가 생성되며, 이중 50.2%가 INCONSISTENT, 49.8%가 CONSISTENT로 분류된다.
평가 과정에서는 1) CNN/DM을 기반(지문이 길고 추출 방식의 요약이 많음)으로 훈련된 요약 모델이 생성한 지문들과 2) XSum 을 기반(추상 방식의 요약문이 많음)으로 훈련된 요약 모델의 생성 지문을 저자들이 직접 사실 관계 일치도를 체크하여 만든 데이터셋을 이용한다.
훈련은 V100 8개를 이용하여, 총 10에폭에 23시간이 소요되었으며, 러닝 레이트는 2e-5를 사용하였다.
4.2 Results
생성한 데이터셋이 사실 관계 일치도에 어떠한 영향을 주는지 확인하기 위하여, BERT를 기반으로 MNLI entailment 데이터와 FEVER 사실 확인 데이터를 이용하여 훈련시킨 모델들을 FactCC/FactCCX 모델과 비교한다.
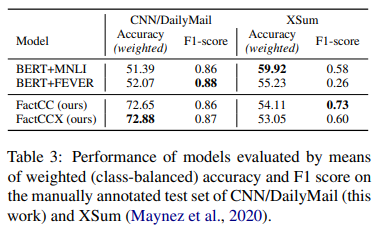
그 결과, CNN/DM 테스트셋에서는 FactCC/FactCCX 모델이 MNLI/FEVER 기반으로 훈련시킨 모델에 비해 훨씬 뛰어난 성능을 보이지만, Xsum 테스트셋에서는 MNLI 모델이 가장 뛰어난 결과를 보인다.
이는 MNLI/FEVER 데이터셋 자체가 대체로 추상 요약에 가까운 문장으로 이루어져 있는 반면, 논문의 데이터셋 생성 과정에서 여러 문장에 대한 패러프레이징 과정이 없기 때문에 자연스러운 결과인 것으로 보인다.
다른 NLI 모델들과 사실 관계 일치도를 비교해보기 위해서 문장별 순위 산출 실험을 진행하였다(Falke et al. (2019)). 이 실험은 기사 문장 하나마다 긍정/부정 문장이 하나씩 쌍으로 주어진다. 목표는 모델이 긍정 문장에 보다 높은 확률을 부여하는 것이다.
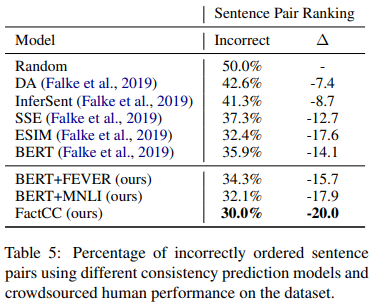
FactCC는 (문서, 문장) 단위로 훈련되었음에도 불구하고 (문장, 문장) 태스크에서도 만족스러운 결과를 내고 있다.
5 Analysis
5.1 Human Studies
FactCCX 모델이 생성하는 하이라이트 구간의 효과를 확인해보기 위한 실험을 수행한다. CNN/DM 테스트셋에서 100개를 선정 후 모델을 통해 (문서, 요약문, 하이라이트) 형태로 생성한다. 이후 각 샘플마다 3명의 사람이 요약문의 사실 일치 여부 판단 과정에서 하이라이트된 구간이 도움이 되는지를 판단하도록 구성하였다. 그 결과, 문서에 포함된 하이라이트는 약 91.75% 의 평가자들이 도움이 된다고 응답하였으며, 요약문에 포함된 하이라이트는 약 81.33% 의 평가자들이 도움이 된다고 응답하였다.
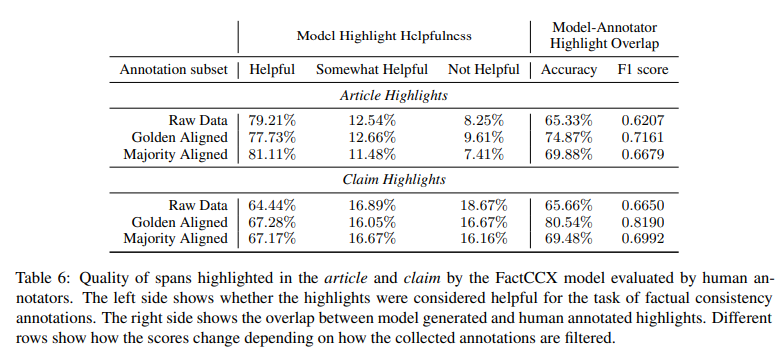
이 과정에서 일부 평가자들의 성향에 따른 편향을 제거하기 위해 세 가지 방식으로 결과를 취합하였다.
- Raw Data : 모든 데이터를 사용
- Golden Aligned : 저자들이 직접 판단한 결과와 평가자들이 판단한 결과가 같은 데이터를 사용
- Majority Aligned : 샘플마다 가장 많이 선택된 결과에 해당하는 데이터만 사용
이런 식으로 필터링해봐도 결과에는 큰 차이가 없는 것으로 나타난다. 이외에도 평가자들이 먼저 하이라이트를 표시한 후 모델이 생성한 결과와 비교하는 실험도 수행하였으며, 이를 통해 모델이 생성한 하이라이트가 상당 부분 사람이 생성한 것과 겹치는 것을 확인하였다.
5.2 Qualitative Study
저자들은 논문에서 제시한 접근 방법의 한계를 명확히 파악하기 위해, 모델이 오류를 범한 예시들을 자세히 살펴보았다. 대다수의 오류들은 사람에게는 아주 쉽지만 논문의 모델은 포착하기가 쉽지 않은 상식에 대한 실수였다.
또한 요약 결과가 매우 추상적일 경우, 특히 여러 문장의 정보를 토대로 판단해야하는 문장일 경우 논문의 모델은 분류를 잘 해내지 못한다. 또한 일시적인 불일치나 부정확한 상호참조 또한 잡아내지 못한다.
Leave a comment